Efficient Peer-to-Peer Keyword Searching
Patrick Reynolds and Amin Vahdat, "Efficient Peer-to-Peer Keyword
Searching,"
Middleware 2003.
Final manuscript:
[PDF]
[PS]
[PS.GZ].
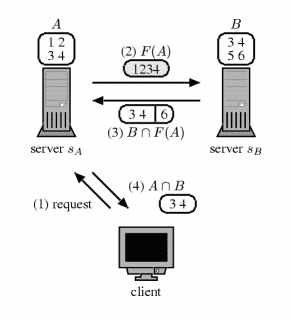 sA and sB are servers storing the
document ID lists for the keywords kA and
kB. A and B are the sets of document IDs
matching the keywords kA and kB.
F(A) is a Bloom filter representation of A.
sA and sB are servers storing the
document ID lists for the keywords kA and
kB. A and B are the sets of document IDs
matching the keywords kA and kB.
F(A) is a Bloom filter representation of A.
Bloom filters help reduce the bandwidth requirement of "AND" queries. The
gray box represents the Bloom filter F(A) of the set A.
Note the false positive in the set B ^ F(A) that server
sB sends back to server sA, which
sA eliminates in order to send A ^ B to
the client.
|
Search is a fundamental part of any complete system for distributing files
and resources. Opaque keys suffice as bookmarks and links, but locating
unknown files by description -- e.g., based on keywords or resource
metadata -- requires search.
The Web's current search infrastructure is limited by its centralized
design and by the pull-based nature of HTTP.
The current move toward peer-to-peer systems for file distribution affords
us the opportunity to improve search substantially. Where Web searching
is centralized, peer-to-peer searching can be entirely distributed, and,
thus, more scalable. Where Web searching depends on crawlers to discover
new or updated content, a peer-to-peer search system can take advantage of
explicit insert operations to build a current index of all networked
content.
Recent research peer-to-peer systems, such as Chord, CAN, and Pastry,
perform mappings from keys to locations in an entirely distributed manner
but provide no search capability. A search system developed for
peer-to-peer systems should itself be distributed, for many of the same
reasons: availability, scalability, and load balancing. One way to build
a distributed search system is to use an inverted index with keywords
evenly distributed among available servers. The primary challenge in
doing so is minimizing the bandwidth required to perform multiple-keyword
searches.
We have designed a distributed inverted index, with particular emphasis on
three techniques to minimize the bandwidth used during multiple-keyword
searches: Bloom filters, caching, and incremental results. Bloom filters
are a compact representation of membership in a set, eliminating the need
to send entire document match lists among servers. Caching reduces the
frequency with which servers must transfer the Bloom filters. Incremental
results allow search operations to halt after finding a fixed number of
results, leaving the cost of searching proportional to the number of
documents returned rather than to the total number of documents in the
system.
We have performed simulations to explore how the system works in practice.
We used a 1.85 GB document set and a 10-day search trace from the web to
investigate word appearance and search frequencies. Word appearance and
search frequencies are roughly Zipf-distributed. The average number of
words searched for is 2.53, and 71.5% of all searches involved two or more
keywords. We simulated several refinements to the basic protocol,
including eliminating the false-positive removal step, using Bloom filters
more selectively, using larger-than-optimal Bloom filters, and having the
client orchestrate the entire search before contacting any servers.